

はじめに
近年では、”ヒト・モノ・カネ”に追加して”情報”という新たな経営資源に対する注目度が高まっています。
「データを使って売上予測をしたい!」と考える企業は多く、これからの時代「情報をどれだけ上手に使えるか」がカギとなるでしょう。しかし、そもそも情報を扱うためには、扱いやすい情報を保有することが重要になります。しかし扱いやすい情報言ってもイメージがつかないかもしれません。そこで今回は、具体的なデータ例を用いて、情報を活用する際に必要となる”正規化”について説明いたします。
これらは反響があれば連載にする予定ですので、もし興味のある方はSNS等で拡散お願い致します。
この記事の対象読者
- データの蓄積のいろはに自信のない方
- データの蓄積は問題なくできているが、データを活用できるほどには至っていない方
- 蓄積しているデータに空欄があり不安を覚えている方
この記事の目的
第1正規化という概念を理解し、システムが取り扱いやすいデータについて紹介します。
クソデータが出来上がるまでの流れ
独立して商売を始めたばかりのAさん。 商売を始めるにあたって収支を次のような考えのもと、売上に関するメモをすることにしました。DX時代ということもあるため、紙を用いずExcelを用いてデータを記録することにしました。
Aさんが考えたこと
Aさんは商売を行うにあたりデータの保管を始めました。最初は日付とデータのみというシンプルなデータだったのですが、以下のような欲が出てどんどんデータを追加していきました。その時の思考の遍歴が以下になります。
- 商売し始めたばっかりだし、とりあえず何月何日に誰がいくら買ってくれたかわかれば十分だよね。
- 1日に複数人のお客さんが来るわけだし、1日複数行に記録しなきゃ。日付一緒のところは見づらいからセルを結合して見やすくしようっと!
- 書く量が多くてたまに被っちゃったり、抜けてるのあるかもしれないけど最終的に一緒なら別に大丈夫か。
- あれ?売上のデータとレジの中身が違う!どこで間違えたのかも忙しいときとか書けてないところもあってわからないよ。どうしよう…。

結局出来上がった売上に関するメモは以下のようなものでした。
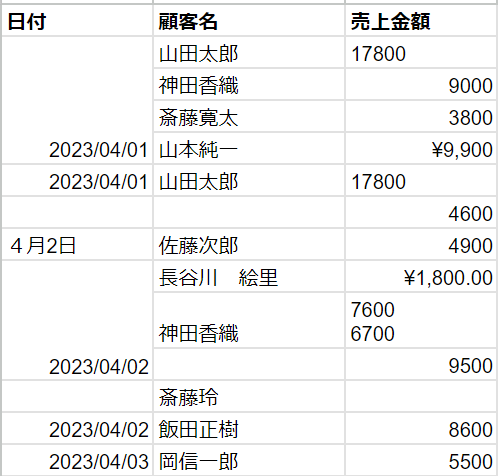
ぱっと見で何か危険な香りがすると識者ならわかるかもしれませんが、良かれと思いデータを作ったは良いけど、結局使いづらいデータが出来てしまい、情報を活用できず経営に支障が出てしまうことがあるかと思います。
こうならないためにはどうすればよかったのでしょう??
何がダメだったのか
なぜAさんの表がダメだったのでしょう。なんとなくダメなのはわかると思いますが、何故ダメなのかを改めて考えてみましょう。
ダメなデータを用いて分析を行ってみると
先ほどのダメなデータから日付別の売上高を可視化するために、縦軸を売上、横軸を日付のグラフを作成していました。
すると、以下のようなデータが出力されました。
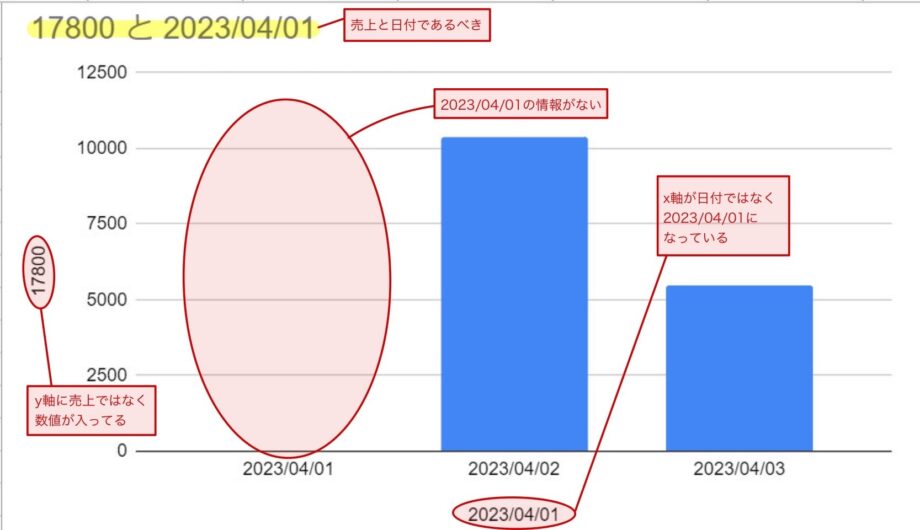
縦軸も横軸も望んでいるものにはなっておらず、横軸に関しては「2023/04/01」の情報が抜け落ちてしまっているという無惨な結果になっておりました。今はサンプルであるため少ないデータ量で済んでおりますが、これがさらに膨大なデータ量になると、何が間違ってるかわからなくなると手の付けようがなくなります。
さらにこのデータを分析するためにPythonのpandasで読み込んでみると
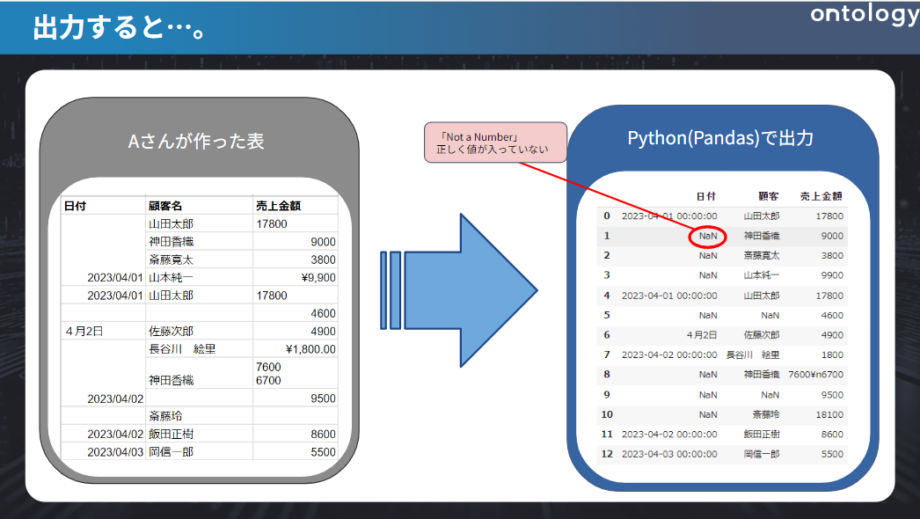
正しく入れているつもりでもNaNで実は入っていませんでした。なんてことも発生します!これはセル結合をした箇所はPythonだと空白であると判定されていしまうため、うまくデータを読み込めないことになります。よくExcelを使う時にセル結合をするなと言われますが、こうしたことを引き起こしてしまうからなんですね。
このようにデータを活用するどころではなく、そもそもデータがクソすぎて使えないという場合が実務では非常に多いです。
一般的に機械判読しづらいデータは以下のようなものが要因になります。
- 情報に被りがある
- 一つのセルに対して複数の情報が入っている
- 列の中で表記が統一されていない
- セル結合している
- 空欄を作っている
以上の事項にて、クソデータが生じてしまいます。
データがごちゃごちゃしない秘訣
前章で挙げたダメになった原因5つは第1正規化ができればまとめて解決できます。
先ほどのデータを第1正規化したら以下のようになります。

ではどのようにしたらこのようなデータになるのか一つずつ見ていきましょう。
原因1:情報に被りがある
このような必要最低限のものに加えて余分や重複がある状態のことを冗長性と言いますが、このデータの場合、冗長性があると無駄なデータ領域と面倒な更新処理を発生させてしまいます。
エピソードのような場合、本当は売れてないのに売れたとして勘定されていたら問題ですよね。そういったことを阻止するためにも冗長性を排除する形を取りましょう。
実は冗長性を排除するためのことはダメになった原因の他4つを解決すれば自ずと解決します。
原因2:一つのセルに対して複数の情報が入っている
一つセルの中に複数の情報を入れると、セル内の値は文字列になってしまいます。つまり、計算や並べ替えなどができないなど、活用する際に余計な手順が増えます。そのため、一つのセルには一つの情報を入れましょう。
原因3:列の中で表記が統一されていない
エピソードで出てきた表で言うと売上金額がわかりやすいです。
本来、数値の列とすべきところが、文字列や¥での表示、小数点以下までの表示など統一されていません。
日付であればしっかりと日付形式の表記を揃えることを徹底しましょう。
顧客であれば顧客名称の表記ゆれを無くしましょう。姓名の間のスペースも半角・全角統一などルールをつくらないと別人として扱われます。
売上金額であれば数値で記載し、数値の記載方法も統一しましょう。
原因4:セル結合をしている
セル結合は絶対にやめましょう。
上記にもある通りセル結合をしてしまうと本来入っているデータが入っていない認識になります。すると、検索や集計の際に漏れてしまい、正しい分析などすべてできなくなってしまうのです。
もちろんやるべきことは明白です。セル結合をしなければいいのです。同じ日付が重複してしまうのが気持ち悪いとおもったのでしょうが、重複してしまうのは機械判読のために望ましいのです。
原因5:空欄を作っている
この空欄はNULL(ヌル)ともいい、本来入っていてほしいところにデータが何も入っていないことを示します。これ絶対悪とまでは言えませんが、NULLの場合は、情報が何もないため「本当は入るのに入っていないのか」 「元々はいるデータがないから入っていないのか」などがわからなくなってしまいます。
少なくとも前者は人が書き忘れたり入力し忘れているため、まずそれは絶対にやめた方がいいです。
後者においてもデータベースやテーブルの設計で無くすことができるためNULLは排除した設計で改善できます。それはまた次以降の記事で解説を行います。
まとめ
このように2~5の原因を解消する手順をすべて踏むことを第1正規化と言います。
第1正規化とあるようにこの後も第5正規化まで存在しますが、今回は第1正規化をすればエピソードでの問題はすべて解消できるのです。
第一正規化が保てるデータを作るためには、以下の事項を守る必要があります。
- 一つのセルに対して一つの属性一つだけ入れる
- セル結合をしない
- 空欄(NULL)を作らない
これらを満たすと一つ目の原因である冗長性の排除にもつながるのです。
最後にこれらを満たしたテーブルの一例がこちらになります。
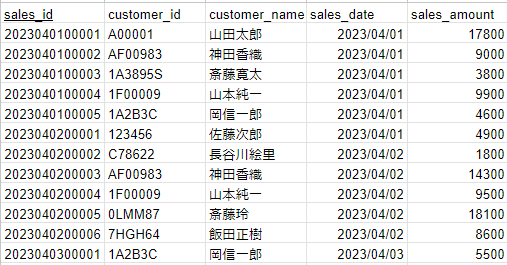
ちょっとデータ量が多くて見づらいかもしれませんが、これらの形式であればピボットテーブルやグラフの作成が容易になります。実務における業務設計は、このような形式のデータがストレスなく貯めることが重要になり、そのための手段がDXといえます。DXについては以下の記事を参考にしてください。
この表の形式でグラフを作成すると、以下の図の右のような形式で出力されます。
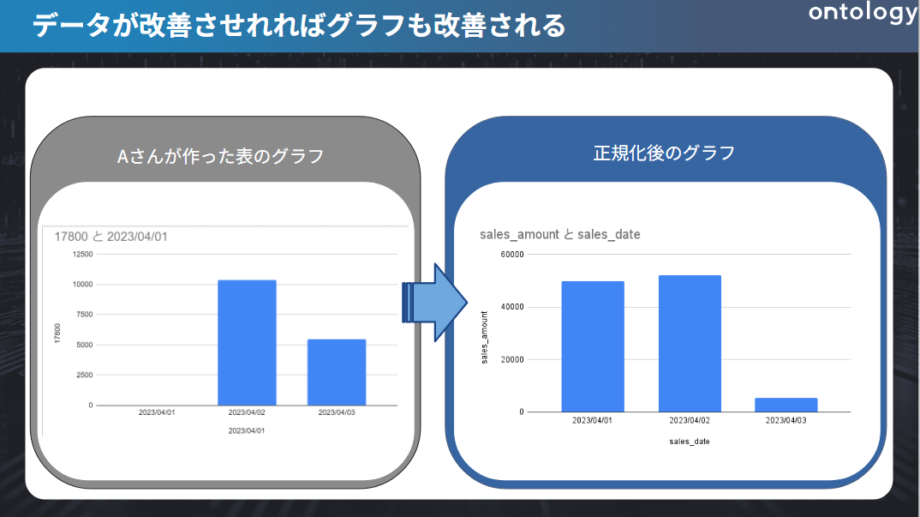
今度は軸も縦軸が売上で横軸が日付と望んだ通りに出力され、 日ごとの売上高がわかるようになりましたね。先程の図解とはうってかわってわかりやすくなりました。
このように正規化された形でのデータの保持を意識することで、後工程でのデータ活用がうまくいくことになります。
まとめ
データを扱う上で大切なのは、機械判読しやすい形でデータを保持することになります。それは正規化された形でデータを蓄積することにほかなりません。皆さんが使っている各SaaSやシステムも、ある意味では正規化されたデータを蓄積するために利用しているものと言えます。
しかし、正規化されたデータを人間が都度入力するのは大変なので、自動的にデータを貯める仕組みが必要といえます。そのための手法がDXと言えると思います。
弊社ではDX推進やシステム構築に関するサポートを行っているため、もしDXを検討している経営者やコーポレートの方がおりましたら、お気軽にお問い合わせください。
おまけ:なぜテーブルでは数字やアルファベットを使うのか
皆さんデータベースを初めに見たときこんなこと思いませんでしたか?
「見づらい…。なんで意味もない数字やアルファベット並べるんだよ。 結局名前とか入れるんだから最初からそれでいいじゃん!」
「人間」が見るか「機械」が見るか
そうなんです。わかりづらいのです。
実はこれデータベースを「人間」が見るのか「機械」が見るのかという違いなのです。
冗長性の排除
コードやIDをは形が統一されています。 例えば「英数字6文字」、「大文字のアルファベットと数字の組み合わせ8文字」などです。
仮に「英数字6文字」であれば、1桁は0~9の10種類 + アルファベット大文字小文字それぞれ26文字ずつ52種類、計62パターンがそれぞれ6桁分なので62^6=56,800,235,584となります。
たかが6桁の数字の羅列でも膨大なパターンが作れるのです。
そのため被りが起こることはあまりないでしょう。少なくとも商品番号などではありえなさそうです。
また、名称の落とし穴にも触れておきましょう。皆さんは「へ」と「ヘ」の違いわかりますか?
どちらかがひらがなでどちらかはカタカナです。
こういった違いは人間にはわかりづらくとも機械にかかれば一目瞭然で区別できるのです。
では人名でも同姓同名の人はどのように区別しますか?
顔写真を載せますか?何年ごとに更新しますか?
また「山田太郎」さんと「山田 太郎」さんは機械からしたら別人として捉えられてしまいます。そういった人と機械の認識の違いによるミスや手間も個人コードや個人IDを設ければ重複をさけ、区別できるのです。
おまけのまとめ
データベースを直接管理しているのは機械です。そのため機械が読めないものは人間だって使えません。
一見読みづらい英数字は、人間と機械をつなぐ架け橋となり、双方が使いやすくするためのものだったのです。




