はじめに
有価証券報告書を読んでいると、「我が国経済は~」から始まる定型文をよく見かけるでしょう。

「うわっ!また『我が国経済』かよ・・・。なんかこの『我が国経済』って書き出しの文章多くね?これどれだけの企業がこの文言を書いてるんだろうか。比率が気になる!」
と考えることはありますよね??、よね?
そこで、我々は6月に提出された有価証券報告書の何割に「我が国経済」が使われているのかを確かめてみました!
一見ネタ分析ではあると思いますが、これらで用いたコードを応用して、業界特有のキーワードや、類似業界における記載例の収集などを調べることにも応用可能かとおもいますので、ぜひこちらを参考にしながらコードを理解頂けると幸いです!
なお、これはネタ分析なので、以下のようなマジレスはご容赦ください・・・!愛のあるツッコミについては、こっそり著者のTwitterかDMでお伝え頂けると幸いです。
- 母集団が発行期間で絞られているはおかしい
- 正規表現の書き方がおかしい
- もっとまともなコードを書け
想定読者
- 有価証券報告書を見たことがある方
- 有価証券報告書での分析等を行っている方
書類別の分析
分析概要
今回求めようとしているのは「2024年6月に提出された有価証券報告書の中で、どれだけの数の有価証券報告書が『我が国経済』という定型文を使っているのか」です。
よって、分析では、提出された有価証券報告書からテキストデータを抽出し、それら一つ一つを”定型文を使用しているもの”と”使用していないもの”で仕分けを行います。
母集団の有価証券報告書のうち、定型文が含まれている有価証券報告書を数えることで分析を行います。
具体的に…
今回の分析では標本の有価証券報告書一つ一つで「定型文が使用されているもの」がいくつあったのかをカウントして使用率を算出します。
※以下使用する式

これらの数を人力でカウントすることは非常に困難であるため。今回はPythonを用いてカウントを行い、定型文使用率の計算を行います。
分析対象について
今回は2024年度6月提出の有価証券報告書にフォーカスしてサンプルを抽出します。
これは、日本の上場企業は3月決算が一番多いこと・有価証券報告書は、おおむね決算から3カ月以内に提出しなければならないことから、選定しました。
なお、提出期間や事業年度によって使用率は変わってくる可能性はあるため、余力のあるかたは調べてみてほしいです。
使用するデータについて
対象とするデータ:2024年6月に提出された有価証券報告書に記述されているすべてのテキストデータ
データの準備
データを用意するために効率化また抽出で間違いが起きないようにするためにPythonを使用してデータの抽出を行います。
データを取得する段階は全部で2段階あります。
- EDINET-APIを使用して提出された日付,fundCode, ordinanceCode, formCodeを指定し条件で絞り込み、XBRLをダウンロードする
- XBRL解析機(edinet-xbrl)を用いて大見出しのテキストを抽出する
*1単語解説より新規単語を参照
以下記事のプログラムコードを使用して6月に提出された有価証券報告書をダウンロードしています。
書類別分析の結果
はじめに答えを言ってしまいますが、2024年6月に有価証券報告書を提出した企業は2519社存在しました。
そしてプログラムをまわした結果、その中から1590社もの企業が「我が国経済」に準ずる用語を使用していることが分かりました(準ずると説明しているのは表記ゆれを考慮した正規表現を利用しているため。正規表現については後述する)。
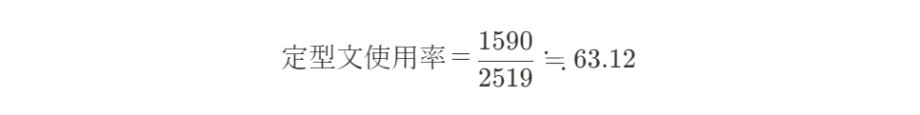
割合で表すと約63.12%もの企業が有価証券報告書のどこかで定型文を使用しているということになります。
書類別分析の内容
分析を行うコード
分析を行うコードは以下の通りです
import os
import re
import glob
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
# 1,XBRLファイルのパスを正規表現で指定し、すべてのファイルパスを取得。pathは分析利用者の環境に合わせて設定してください
xbrl_file_paths = glob.glob(r"XBRL_files\\Xbrl_Search_2024*\\*\\XBRL\\PublicDoc\\*.xbrl")
# 2,正規表現パターンをコンパイル
pattern = re.compile(r'(わが国|我が国)[^\\s]{0,1}経済')
# bとdの補助, 全ファイル中のマッチ数とファイル総数をカウントする変数
total_files = 0
matching_files = 0
# 3,各企業ごとに処理
for file_path in xbrl_file_paths:
try:
# a,XBRLファイルをパースしてxbrlオブジェクトを作成
xbrl = EdinetXbrlParser().parse_file(file_path)
# 全てのキーを取得
keys = xbrl.get_keys()
# ファイル全体のテキストを結合
full_text = ""
for key in keys:
data_list = xbrl.get_data_list(key)
for data in data_list:
value = data.get_value()
if value is not None:
full_text += value
#b,すべての企業数をカウント
total_files += 1
# c,ファイル全体のテキストに対してパターンを検索
if pattern.search(full_text):
#d,パターンがマッチしていたら数字をカウントする
matching_files += 1
#予想外のエラーが起きた時にその内容を表示する
except Exception as e:
print(f"Error processing file {file_path}: {e}")
# 4,パターン的中率を計算
match_rate = (matching_files / total_files) * 100 if total_files > 0 else 0
#5, 結果を表示
print(f"企業数: {total_files}")
print(f"定型文が使用されていた企業数: {matching_files}")
print(f"定型文使用率(%): {match_rate:.2f}%")
Code language: PHP (php)出力結果
以下の画像のような出力画面が出てきます。

解説
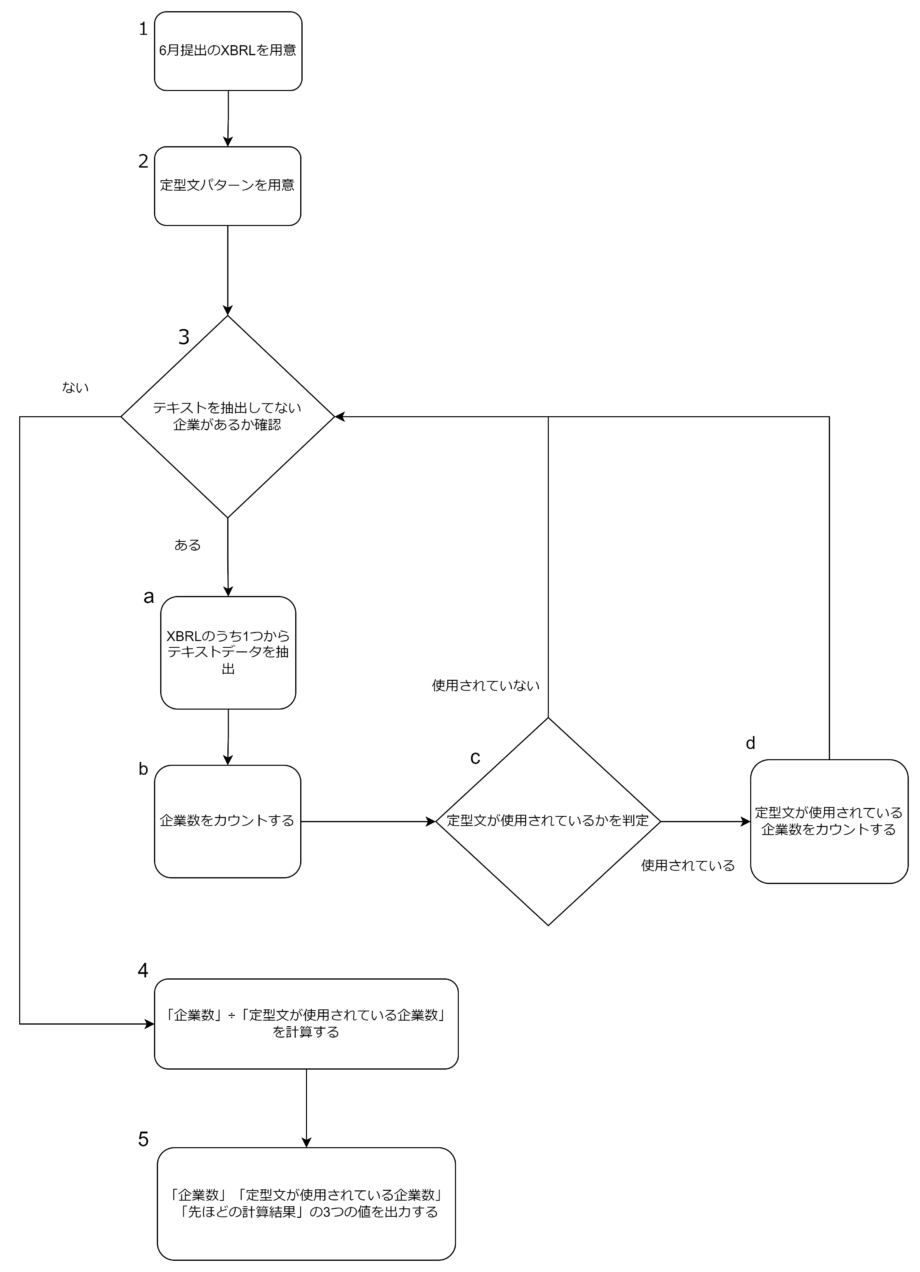
システムの流れは、
- EDINET APIを用いてXBRLをDLする
- 定型文のパターンを用意する
- a : XBRL一つ一つのテキストデータを抽出
- b : 企業の総数をカウントする
- c : 定型文パターンとマッチしているかを判定する
- d : 定型文がマッチしていたら企業数をカウントをする
- a~dまでをすべてのXBRLファイルに対して行う(繰り返し処理)
- ”最終的なbの数値”÷”最終的なdの数値”を計算する
- ”最終的なbの数値”と”最終的なdの数値”と”4で計算された数値”を出力する
です。
2のプログラムで定型文を抜き出すための方法
2では定型文のパターンを用意すると説明しました。
なぜこのようなパターンを用意するのかというと、今回の定型文「我が国経済」では複数の表記ゆれが存在するからです。
定型文といっても明確に文字列が定義されているわけではありません。「我が国経済」であったり「我が国の経済」であったり「わが国経済」であったりします。
このような場合、自分たちでパターンをすべて洗い出してみるのも一つだと思いますが、やはり人力では抜け落ちるパターンがあるかもしれません。
そこで、これらの表記ゆれに共通するパターンを見つけ出しプログラムにパターンに一致するものをすべてを持ってきてもらうのための表現である正規表現を用いることで、人力でなくともパターンマッチしたものを抽出することが可能です。
今回であれば以下のコードを使用しました。かっこ内が正規表現となっております。
pattern = re.compile(r'(わが国|我が国)[^\\s]{0,1}経済')
Code language: JavaScript (javascript)このコードでは
- わが国 or 我が国 という文字列が使われている
- 1の文字列の後に0文字 or 1文字の何かしらの文字列が入る
- 2の文字列の後に経済という単語が使われている
といったパターンを指定しています。
プログラムではこのパターンに一致するものすべてを定型文として認識して、条件に合致するものがヒットします。
書類別分析の結論
以上で分析が完了しました。
その結果、約6割の企業が「我が国経済」使用しているということが判明しました。多いと感じるか少ないと感じるかは受け手次第ではありますが、中々の数ですね。
全体の企業数でいったら約6割ではありますが、業種とか事業年度数とかで切り口を変えてみたら、また違った結果になるかもしれませんね。
まとめ
今回は「我が国経済」がどれだけの企業に使われているのかを分析してみました。
個人的には、肌感覚で「なんとなく多いなー」が数値化されたことで「やっぱ多いなぁ」と確信に変わりました笑。
多くの企業が定型文を使用していて、企業は経済状態に言及したうえで行動をすることが求められているのだと再認識しました。
ここまで分析すると、有価証券報告書のどの項目に「我が国経済」が使用されることが多いのか気になるぅぅ!
ということで、次回では有価証券報告書の項目別での”「我が国経済」使用率”を考えていこうと思います。
次回作にご期待ください!
*1単語解説
EDINET-API
直接EDINET画面に行くのではなく、プログラムを介してEDINETに提出された開示情報をダウンロードできるもの
※詳しくは先ほどの上記記事に書いてあるので確認してみてください。
XBRL
企業の提出書類の内容をプログラムで読込みやすくしたファイルの総称。
EDINETで誰でもダウンロードすることができる。
fundCode
EDINET APIの使用においてファンドが提出した開示書類に対して付けられる番号。
ファンドではない上場企業などの場合は値がNone(何も番号が付けられていない)状態になる。
ordinanceCode
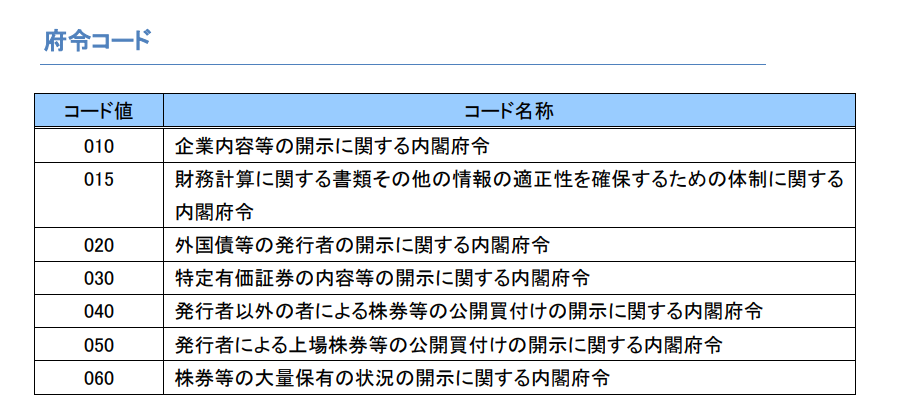
EDINET APIの使用において開示書類に適用された内閣府令を表す番号。
以下の画像のように内閣府令ごとに番号が付けられている。
引用:EDINET API仕様書(version2)p85
formCode
EDINET APIにおいて開示書類に適用された様式を表す番号。
以下の画像のように、内閣府令ごとに「第〇号の△様式」といった形で同じ書類でも様々な表示形態が存在する。
同じ種類の開示書類でも複数の記述方法が存在するためそのそれぞれのことを様式と呼んでいる。
引用:https://www.fsa.go.jp/search/20231211.htmlよりタクソノミ要素リスト.xlsx

XBRL解析機(edinet-xbrl)
Pythonで使用するライブラリです。
このライブラリで見出し(XBRLタグ)を指定することでそれに応じたテキストや数値を得ることができます。