はじめに
今回記事は以下掲載の記事の続編になります。
そちらをご覧になってからのほうがこの記事をお楽しみいただけます。
「うわっ!また『我が国経済』かよ・・・。なんかこの『我が国経済』って書き出しの文章多くね?これどれだけの企業がこの文言を書いてるんだろうか。比率が気になる!」
と考えることはありますよね??、よね?
ということで、前回の記事では有価証券報告書内で「我が国経済」がどれだけの企業に使われているのかを分析しました。
企業別での使用率が分かり「ん?そういえば、どの項目で「我が国経済」が多く出てくるんだ??思い返せば、複数の項目で見たことあるな…。」
と、気になりましたよね?、、よね?
なので今回は、少し深ぼり有価証券報告書の項目別での「我が国経済」の使用率を確かめてみました!
なお、これはネタ分析なので、以下のようなマジレスはご容赦ください・・・!愛のあるツッコミについては、こっそり著者のTwitterかDMでお伝え頂けると幸いです。
- 母集団が発行期間で絞られているはおかしい
- 正規表現の書き方がおかしい
- もっとまともなコードを書け
想定読者
- 有価証券報告書を見たことがある方
- 有価証券報告書での分析等を行っている方
項目別の分析
分析概要
今回の分析では「”我が国経済”がどの項目で一番使用されているのか?」を考えていこうと思います。
項目については、この記事では有価証券報告書等を見た際中に書いてある見出しのこと、又は勘定科目等のことと定義します。専門的な用語だとタクソノミです。
タクソノミについては以下記事をご覧ください。
前作では有価証券報告書の中からデータの抽出を行いましたが、そこではすべてのデータを使用していたところを、項目別でテキストデータの抽出を行い定型文の使用有無を判定します。
有価証券報告書単位ではなく項目別に集計を行い、それぞれの項目での使用率を算出していこうと思います。
具体的に
今回はPythonで集計を行った後に集計データをExcelに移動して、そこで使用率等を確認していきます。
有価証券報告書の項目数は非常に多くプログラムでの出力ではすべての確認が難しいため、Excelを使用します。
また、以下の式を使用して項目ごとの使用率を求めていきます。

分析対象について
母集団:2024年6月に提出された有価証券報告書の項目ごとのテキストデータ
対象:全数
使用するデータについて
対象とするデータ:項目ごとに分けた有価証券報告書のテキストデータ
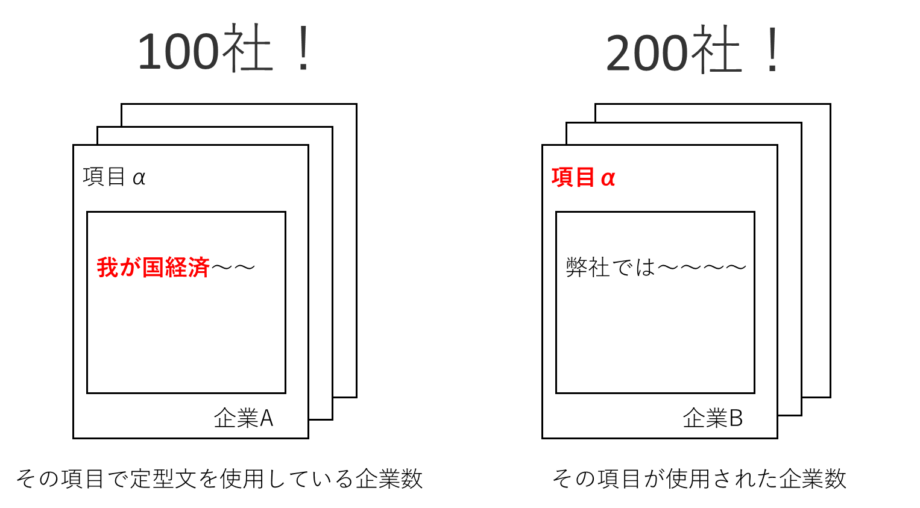
集計方法:項目ごとに「その項目で定型文を使用している企業数」「その項目が使用された企業数」をカウントする
※有価証券報告書では企業ごとに使用される項目に違いが出るためこの2つの数値を算出する。
データ準備
使用するデータは前作でダウンロードしたXBRLです。
XBRLには項目別で内容を分けて情報を持ってくることが可能です。
※XBRLについては以下記事からご覧ください。
項目別分析の内容
分析を行うコード
import os
import re
import glob
import pandas as pd
from bs4 import BeautifulSoup
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
# 1,XBRLファイルのパスを正規表現で指定し、すべてのファイルパスを取得。pathは分析利用者の環境に合わせて設定してください
xbrl_file_paths = glob.glob(r"XBRL_files\\*\\*\\XBRL\\PublicDoc\\*.xbrl")
# 2,正規表現パターンをコンパイル
pattern = re.compile(r'(わが国|我が国)[^\\s]{0,1}経済')
selection_pattern = re.compile(r".+[。!?]")
# 結果を保存する辞書
key_results = {}
# 3,各ファイルごとに処理
for file_path in xbrl_file_paths:
try:
# XBRLファイルをパースしてxbrlオブジェクトを作成
xbrl = EdinetXbrlParser().parse_file(file_path)
# a,全てのキーを取得
keys = xbrl.get_keys()
#4、 各キーに対してデータを取得し、処理
for key in keys:
data_list = xbrl.get_data_list(key)
#ⅰ,テキストデータを抽出する
for data in data_list:
value = data.get_value()
if value is not None:
# BeautifulSoupを使ってHTMLからテキストを抽出
soup = BeautifulSoup(value, 'html.parser')
text = soup.get_text(separator='\\n')
# strip()で先頭と末尾の空白を削除し、正規表現で連続する空白を1つにまとめる
text = text.strip()
text = re.sub(r"\\n","", text)
text = re.sub(r'\\s+', ' ', text)
#ⅱ,2つ以上の文章が使用されているキーに絞る
if re.search(selection_pattern, text):
if key not in key_results:
key_results[key] = {
"Total keys": 0,
"Total Matching Docs": 0
}
# ⅲ,文書全体のカウントに加算
key_results[key]["Total keys"] += 1
# ⅳ,パターンに一致するかをチェック
if pattern.search(text):
#ⅴ,パターンに一致するものをカウントする
key_results[key]["Total Matching Docs"] += 1
else:
# 削除前に存在を確認してから削除
if key in key_results:
del key_results[key]
except Exception as e:
print(f"エラーが発生しました: {file_path} - {e}")
print(key_results)
df = pd.DataFrame.from_dict(key_results, orient='index')
#5,その項目で定型文を使用している企業数 ÷ 抽出した項目が使用されている企業数の計算を行う
df['Matching Percentage'] = df['Total Matching Docs'] / df['Total keys'] * 100
excel_path = 'xbrl_key_analysis_results.xlsx'
# 6,データをExcelに保存
df.to_excel(excel_path, index=True)
print(f"Excelファイルが保存されました: {excel_path}")
Code language: PHP (php)解説
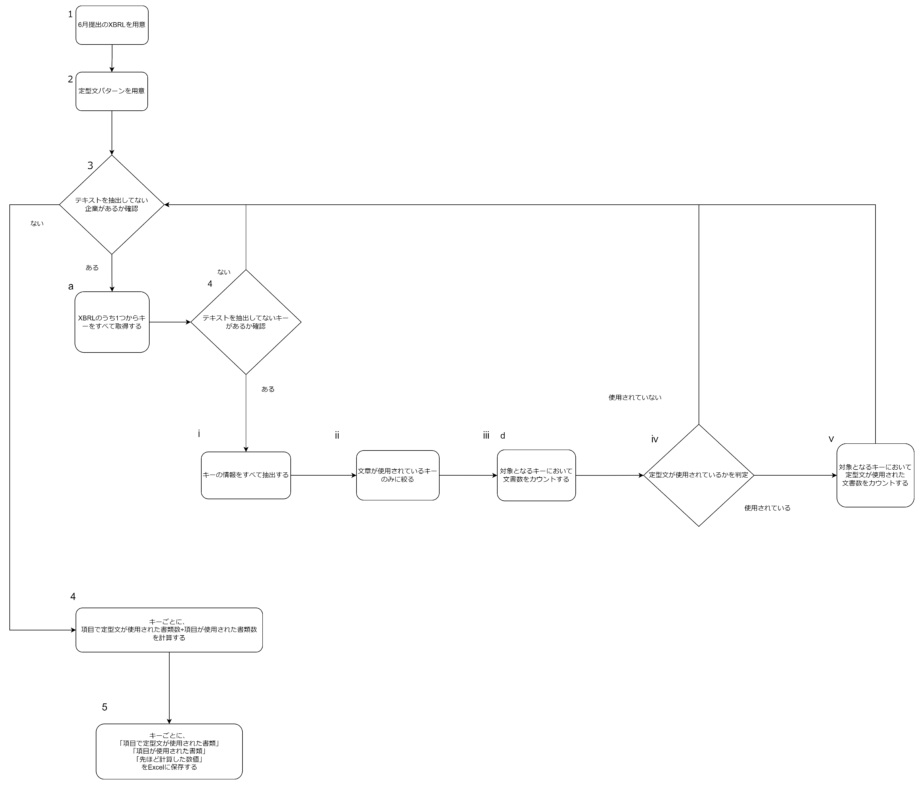
システムの流れは、
- XBRLを用意する
- 定型文とキーのパターンを用意する
- a : XBRL一つ一つのキーをすべて抽出
- ⅰ : キー一つ一つの中のテキストデータを抽出する
- ⅱ : 文章が使用されているキーのみに絞る
- ⅲ : キー別での企業の総数をカウントする
- ⅳ : 定型文パターンとマッチしているかを判定する
- ⅴ : 定型文がマッチしている企業数のカウントを行う
- a : XBRL一つ一つのキーをすべて抽出
- aをすべてのXBRLファイルに対して行う(繰り返し処理)
- ⅰ~ⅳをすべてのキーに対して行う(繰り返し処理)
- ”最終的なⅱの数値”÷”最終的なⅳの数値”を計算する
- ”最終的なⅳの数値”と”最終的なⅳの数値”と”4で計算された数値”をExcelに保存する
です。
ⅱのプログラムを使用する理由
このプログラムでは、「我が国経済」の定型文は財務データ等には書かれておらず文章の中に登場しているものであるため、抜き出すものをテキストデータに限定しています。
主に正規表現と呼ばれる技術を使用しましたが、その理由は使用するデータをテキストデータのみに絞り込むためです。
ここでいうテキストデータとは、具体的には文章データのことです。
有価証券報告書では「事業等のリスク」や「経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析」などの項目が文章で記述されています。
正規表現ではこれら文章データのみに共通するパターンを指定することで、データが文章データなのかどうかを判定することができます。
今回は文章に共通するパターンとして、日本語の文章を記述する際に文末で使用される「。」「!」「?」が使用されているものを文章としてプログラムに認識させます。
よって、「。」「!」「?」のいずれかを含むデータを保有しているキー(項目別に付けられているidのようなもの)を正規表現で判定し文章データであるものをカウントします。
以下の正規表現を使用して、「。」「!」「?」のいずれかを含むデータを保有しているキーのみを抜き出しています。
selection_pattern = re.compile(r".+[。!?]")
Code language: JavaScript (javascript)出力結果
以下のようなExcelがダウンロードされました。

A列にかかれているのがキーでありXBRLではタグといわれるものです。
勘定科目や見出しなどの項目別に統一のものが定められています。
また、一番下まで見てみると5571行目までデータが存在しました。
ただデータのほとんどがTotal Matching Docsが0と出ていることが確認できます。
見やすいようにExcel機能でフィルターをかけ、定型文が1つでもマッチしていた項目だけを抜き出してみましょう。

1つ以上定型文が使われている項目は全部で13個しかありませんでした。
結論
一番多く使われていたのは、「jpcrp_cor:managementanalysisoffinancialpositionoperatingresultsandcashflowstextblock」
「経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析 [テキストブロック]」
で全2519社すべてに使われている項目であり、そのうち1499社が定型文を使用していました。
定型文使用率は59.51%です。
また、見やすく日本語での項目名に直してみました。

項目で分けなければ約63%の企業が定型文を使用していたと前回の分析で結論が出たので、そのうちのほとんどがこの項目で定型文を使用していたといっても過言ではありません。
また、定型文が使用されたものの文書数を項目別で円グラフにして割合的に出してみると、先ほどの項目は80%と大半を占めていたことが分かりました。
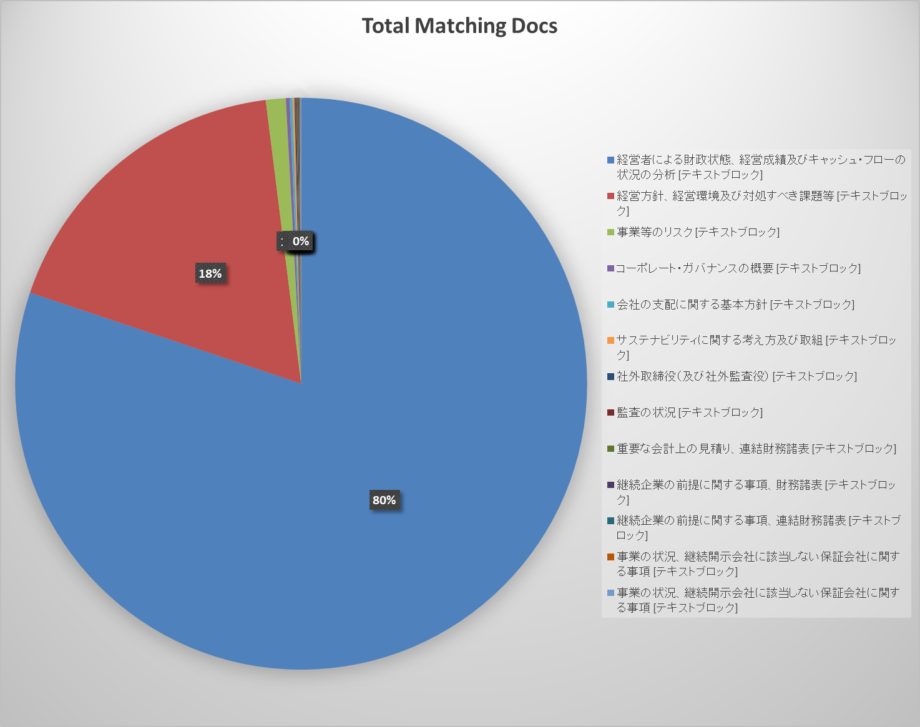
2番目に多く使用されていた項目は
「jpcrp_cor:businesspolicybusinessenvironmentissuestoaddressetctextblock」
「経営方針、経営環境及び対処すべき課題等[テキストブロック]」
であり定型文使用率は13.26%です。
使用されているキーの中では18%使用されていることが確認できます。
経営に関わる項目で日本の経済状態について触れられることが多いようです。
当然と言えば当然でしょうか。
有価証券報告書は、宝印刷やプロネクサスのサービスを用いて作成することがほとんどであり、それらのテンプレートに「我が国経済」という言葉が用いられているから、多くの企業が記載しているのかもしれないですね。
また、Twitterの有識者によると、経団連が用いていた雛形に「我が国経済」が用いられていたらしいです。
まとめ
今回は前回記事と比べ ”項目別での使用率を求める” という一歩踏み込んだ分析を行ってみました。
やはり「経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析」に一極集中していましたね。
逆に、ほとんどの企業で使われていない項目で使用されている場合はどのような内容に言及するのに定型文が使用されているのか気になってきました。このあたりを抽出して良く使われる単語をピックアップしてみるのも面白いかもしれませんね。
今回はネタ分析となりますが、読者の皆様に楽しんでいただき、新たな分析につなげていただければ幸いです。