

はじめに
世の中の上場企業は自身の会社の状況を決算短信や有価証券報告書(以下、有報)などを用いて説明する義務があります。
株主や投資家は有報などを見て、企業を分析し、投資を決心をします。
しかし、有報は1社につき約100ページ程度、提出数は年間4000件程度あります。そのすべてチェックするというのはいささか現実的ではありません。
そこで財務報告書のファイル形式であるXBRLについて知り、知りたい情報だけをより簡単に取って来ることが出来ると楽ですよね。
なるべく楽によりたくさんの情報を集め、分析できるようになることが本シリーズの共通の目的となります。
本連載では、
- 有報など見るけど、必要な情報を自分の目で見に行っている人
- XBRLについて今は全く知らないけれど理解を深めたいと思っている人
- 有報の分析を楽にしたい人
こういった人に向けて執筆しています。
前稿までは、XBRLについて概要や特徴、取得する対象である有報について知識をつけてもらいました。さらに分析に必要な有報を大量にダウンロードする方法について扱ってきました。
まだ前稿を読まれてない方はこちら
まるっとわかるXBRL入門シリーズ
前稿までで分析に必要な準備は十分にできたと思います。分析対象などの準備はした上でこの記事を読んでいただいた方がスムーズだと思います。 今回からは実際に有報の中からデータを取得していきます。
今回、取得するのは財務データです。財務データとは簡単に言うと数値で表せるお金の情報のことです。売上高、収益、資産、負債などなど。
そういったお金にまつわる数字のデータを今回は取得していこうと思います。
動作環境
OS: Windows 11
Python 3.12.4
edinet_xbrl 0.2.0
Github
https://github.com/ryou-naruki/XBRL_Foundnation_from_Ontology
1社から取得してみる
コードを書いて任意の情報を取得してみます。 一気に何社も取得すると理解がしづらいのでまずは一つの企業に限定して情報を取得していきましょう。
今回、トヨタ自動車株式会社を例に用いて情報を取得してみます。 そして、取得する情報は売上高で行います。なお今回はトヨタ自動車株式会社の形式を軸に分析します。トヨタ自動車では日本会計基準で財務諸表を作っているのが連結財務諸表ではなく、単体財務諸表のため、取得書類は、日本会計基準の単体財務諸表に合わせるものとします。*¹
昨今、IFRSで財務諸表を作成している大企業は増えているもののすべての企業がIFRSで作成しているわけではありません。そのため、今回はまだ数の多い日本会計基準を対象の分析を採用しました。
*1 トヨタでは連結財務諸表はIFRS(国際会計基準)で作成されています。
タクソノミを確認
まず、情報を取得するためには有報内でその情報を特定するためのタクソノミのタグを指定しなくてはなりません。そのタグを調べていきます。
今回は、以前の記事で紹介した方法の1つ目の方法を使用します。 これは財務情報のタグを比較的探しやすい方法だと思っています。
▼他のタクソノミの参照方法など詳しくはこちら まるっとわかるXBRL入門:(2) タクソノミと有報
まずはEDINETから任意の有報をダウンロードする画面で、「CSV」をダウンロードしましょう。
その中から圧縮サイズが一番大きいファイルを開き以下のような表を参照できる状態にしてください。
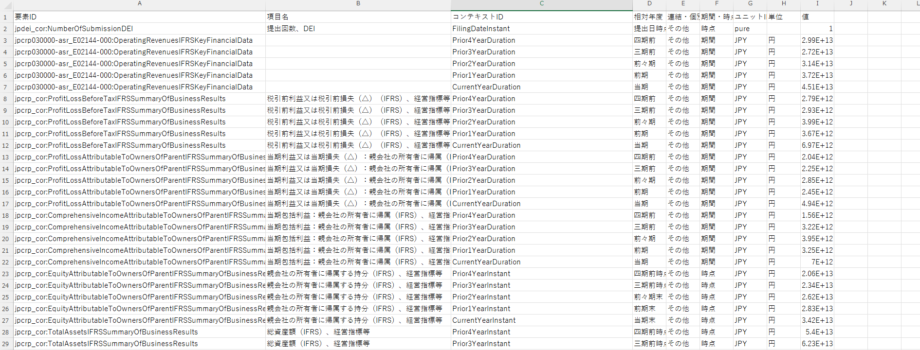
ざっくりとこの表の見方を言うと、
- 「要素ID」= タグ
- 「項目名」= 勘定科目や目次など
- 「コンテキストID」= コードのcontext_refに対応するもの、期間や連結・個別を示すもの
- 「相対年度」=コンテキストIDに対応する期間
- 「連結・個別」=子会社も合わせたグループ会社全体のものかその企業の個別の
その他はカラム通りの意味です。特に大事になって来るのが以上の5つです。 項目名と相対年度に対応する要素IDとコンテキストIDの2つで有報の中から一つの情報に絞り込んでいます。 ただし、その2つがぱっと見ではわからない場合もあるため、他の3つのカラムを参照し正しい要素IDとコンテキストIDを指定できる状態にします。
まずは「項目名」が売上高の項目の行を検索をかけて探しましょう。
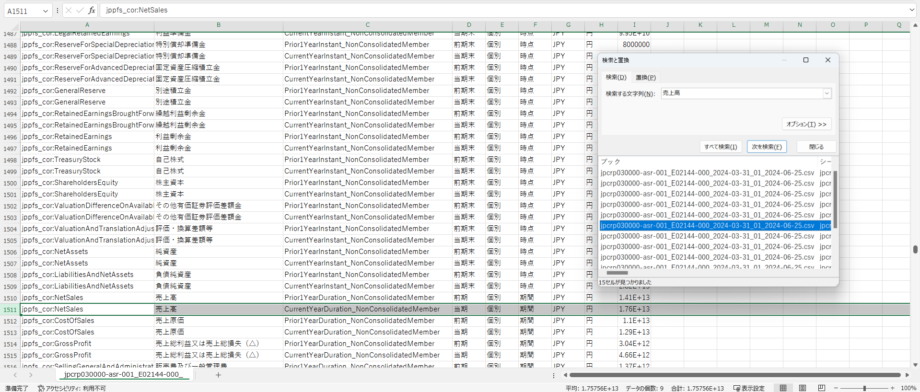
検索窓を見ると16個のセルにて「売上高」という文字列が発見されました。 すべて見ていただければわかるのですが、実は売上高という文字が入っているのは項目名の列だけではありません。 「値」といういわゆるインスタンスの部分にテキストデータとして入っているケースも検出されるので惑わされないようにしてください。今回探しているのは、勘定科目(=項目名)が売上高のものです。
以上で調べたように今回は、単体財務諸表から売上高を抽出したいため、
要素IDが ”jppfs_cor:NetSale”、
コンテキストIDが ”CurrentYearDuration_NonConsolidatedMember”
と指定して取得を試みます。*²
項目名が任意の勘定科目と期間のタグがわかったらそちらをメモしておきましょう。 次のコーディングでそれを使用します。
*2 期間を表すコンテキストIDが何を指すのかについては表の右隣の相対年度の列を参照してください。要素名、項目名が全く同じであってもこのコンテキストIDが違うと年度が違うということです。多くの場合、最新の情報を求めるため、「当期」を取得することが多いと思います。
ソースコード
このコードは同じディレクトリ内に分析対象の書類が準備され、ファイルが解凍されている状態を想定しています。
XBRLファイルのダウンロード方法は前回の記事解説しています。
▼まだの方はこちらから
まるっとわかるXBRL入門:(3)大量の有報を自動でダウンロードしよう
# xbrlfile_financial_basic.py
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
parser = EdinetXbrlParser()
# 対象のXBRLファイルを指定
xbrl_file_path = "xbrl_file/Xbrl_Search_20240820_133855/S100TR7I/XBRL/PublicDoc/jpcrp030000-asr-001_E02144-000_2024-03-31_01_2024-06-25.xbrl"
edinet_xbrl_object = parser.parse_file(xbrl_file_path)
# 対象企業の売上高を取得
key = "jppfs_cor:NetSales"
context_ref = "CurrentYearDuration_NonConsolidatedMember"
try:
current_year_assets = edinet_xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
print(f"売上高: {current_year_assets}")
except Exception as e:
print(f"データの取得に失敗しました。:{e}")Code language: PHP (php)解説
XBRLを使用して情報を取得するために使用するPythonのライブラリはいくつかあります。 今回はバフェット・コードを作った方が作成したライブラリ「edinet-xbrl」というライブラリを使用します。
# 対象のXBRLファイルを指定
xbrl_file_path = "xbrl_file/Xbrl_Search_20240820_133855/S100TR7I/XBRL/PublicDoc/jpcrp030000-asr-001_E02144-000_2024-03-31_01_2024-06-25.xbrl"
edinet_xbrl_object = parser.parse_file(xbrl_file_path)Code language: PHP (php)xbrl_file_pathに準備しておいたXBRLファイルのパス(保管場所)を指定します。
VS CodeでXBRLファイルを見つけて右クリックをすれば「パスをコピー」があるのでそこから引っ張ってきましょう。
# 対象企業の売上高を取得
key = "jppfs_cor:NetSales"
context_ref = "CurrentYearDuration_NonConsolidatedMember"
try:
current_year_assets = edinet_xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
print(f"売上高: {current_year_assets}")
except Exception as e:
print(f"データの取得に失敗しました。:{e}")Code language: PHP (php)次に、取得したい情報について指定するために”key”と”context_ref”を指定します。 “key”とはタグを表す部分で、先ほどタクソノミを確認したときの「要素ID」に当たるものです。 ”context_ref”は期間などを表す部分で「コンテキストID」に当たるものです。
これら2つを正確に指定することで情報を取得できます。
なお、”context_ref = “CurrentYearDuration_NonConsolidatedMember””の「_NonConsolidatedMember」は個別を意味しており、これだけで連結の情報は取得しないようになっています。
わかりやすく表示するためのprint文と失敗したとき用に動くけどエラー文も吐き出すように準備しましょう。
結果
ターミナル上
売上高: 17575593000000Code language: HTTP (http)上記のコードを回すことで正常に売上高を取得することができました。 ではこの取得した情報が間違っていないか念のため有報を比較してみましょう。
有報との比較
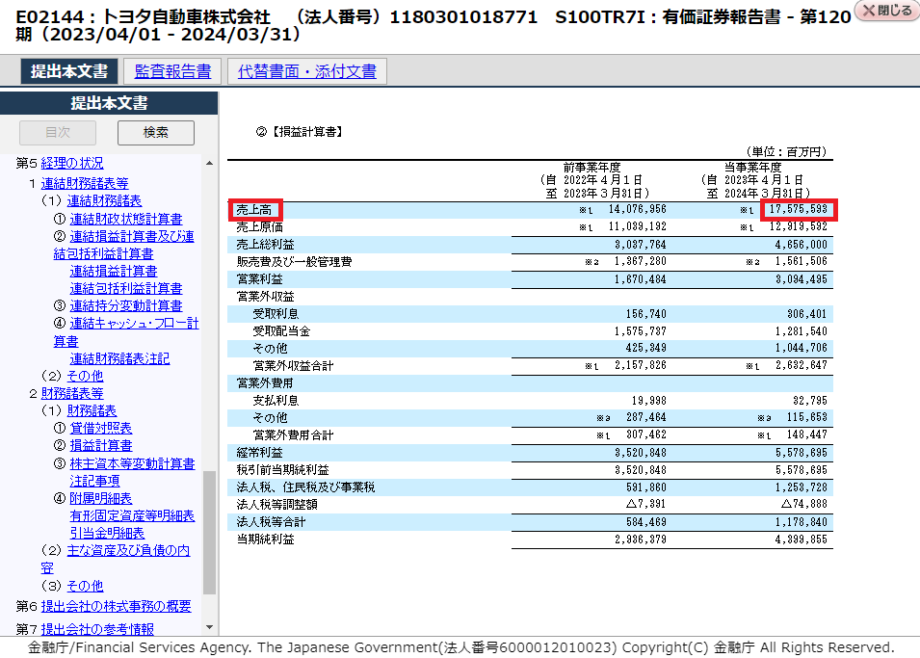
表の右上に単位が書いてあり、これが百万円になっています。桁数が異なっているのはこのためです。つまり、正常にデータが取得できています。
もし有報と取得した情報が異なっている際には、指定しているタグや期間が間違っているかもしれません。有報を見比べたときに近くの情報などと見比べてあっているか確認してみることをオススメします。
10社から取得してみる
より実用的にするために上記のコードを少し改良し、同じ処理を繰り返し実行することで対象企業を10社に増やしてみましょう。
今回対象にする企業は以下の超大手の10社です。
- トヨタ自動車株式会社
- ソニーグループ株式会社
- 三菱商事株式会社
- ソフトバンクグループ株式会社
- イオン株式会社
- 株式会社ファーストリテイリング
- パナソニックホールディングス株式会社
- 日産自動車株式会社
- 日本郵政株式会社
- KDDI株式会社
ソースコード
先ほどのコードと異なる点はファイルパスのところを1社から10社に増やしリスト化します。 さらに処理を1社ずつすべての企業で行うためfor文を使用します。
抽出する情報は引き続き「単体財務諸表から売上高」で行います。
そのためタグは 勘定科目のタグ(要素ID)が ”jppfs_cor:NetSale”、 期間のタグ(コンテキストID)が ”CurrentYearDuration_NonConsolidatedMember” のまま指定します。
# xbrlfile_financial_10companies.py
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
def get_revenue_from_xbrl(file_path, key, context_ref):
# XBRLファイルから売上高を取得する関数
parser = EdinetXbrlParser()
try:
xbrl_object = parser.parse_file(file_path)
revenue = xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
return revenue
except Exception as e:
return f"データの取得に失敗しました。:{e}"
# 10社分のXBRLファイルパスをリストにまとめる
xbrl_file_paths = [
"xbrl_file\\Xbrl_Search_20240820_133855\\S100TR7I\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02144-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_133918\\S100TS7P\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01777-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134037\\S100TL6G\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02529-000_2024-03-31_01_2024-06-21.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134126\\S100TP3N\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02778-000_2024-03-31_01_2024-06-21.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134142\\S100TG6G\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E03061-000_2024-02-29_01_2024-05-30.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134227\\S100SD9V\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E03217-000_2023-08-31_01_2023-11-30.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134244\\S100TQZC\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01772-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134257\\S100TXFX\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02142-000_2024-03-31_01_2024-06-28.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134311\\S100TO15\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E31748-000_2024-03-31_01_2024-06-20.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134355\\S100TN7R\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E04425-000_2024-03-31_01_2024-06-20.xbrl"
]
# 対象企業の売上高を取得
key = "jppfs_cor:NetSales"
context_ref = "CurrentYearDuration_NonConsolidatedMember"
# 各企業から売上高を取得
for i, file_path in enumerate(xbrl_file_paths):
revenue = get_revenue_from_xbrl(file_path, key, context_ref)
print(f"企業{i+1}の売上高:{revenue}")Code language: PHP (php)行っている処理自体は先ほどと同じです。 ただし、10件あるため、10件分のパスの指定と指定されたファイルをfor文で処理されるようにしているのです。
結果
ターミナル上でエラー
企業1の売上高:17575593000000
企業2の売上高:158726000000
企業3の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業4の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業5の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業6の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業7の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業8の売上高:4187227000000
企業9の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'
企業10の売上高:データの取得に失敗しました。:'NoneType' object has no attribute 'get_value'Code language: JavaScript (javascript)10件中3件しか売上高の情報を取得できませんでした。
取得に失敗した企業のアウトプットをを見ると、TypeがNonetypeと書いております。 簡単に言うと、インスタンスをうまく取得できなかった、つまり「指定したタグの中に何も入っていないところがあったから動かないよ」というエラーです。
なぜこのようなエラーが出るのでしょうか? これは、「使われているタグ=勘定科目」が異なっているために起こってしまっています。
個別財務諸表で「売上高」を使っている会社は、3社しかありません。 他の会社は「営業収益」など別の勘定科目を用いています。他にもそもそも連結や会計基準がIFRSであるものも異なるものとして識別されている(もちろんタグも違う)ことが原因で全ての企業から情報が取得できていません。
なぜ多くの企業で取得が失敗したのか、原因を探ると以下のようだとわかりました。
| 企業名 | 結果・特徴 |
|---|---|
| トヨタ自動車株式会社 | 個別で取得成功。連結はIFRS。 |
| ソニーグループ株式会社 | 個別で取得成功。 |
| 三菱商事株式会社 | 個別の科目が「売上収益」であったため取得失敗。 |
| ソフトバンクグループ株式会社 | 個別の科目が「営業収益」であるため取得失敗。 連結で「売上高」はあるが、IFRS(国際会計基準)であるため 比較不可能(IFRSだとタグも異なる)。 |
| イオン株式会社 | 個別が持株会社のため取得失敗。 連結だと売上高(タグも同じもの)がある。ただし、コンテキストIDが違うため取得できていない。 |
| 株式会社ファーストリテイリング | 個別の科目は「営業収益」であるため取得失敗。 連結で「売上収益」でありIFRS。 |
| パナソニックホールディングス株式会社 | 個別の科目が「営業収益」であるため取得失敗。 連結で「売上高」はあるがIFRS。 |
| 日産自動車株式会社 | 個別で取得成功。 個別の科目でも連結の科目でも「売上高」がある。 |
| 日本郵政株式会社 | 科目が違うため取得失敗。「売上高」という科目がない。 |
| KDDI株式会社 | 個別の科目は「営業収益」であるため取得失敗。 連結で「売上高」であるがIFRS。 |
これらをまとめるとタグが違うから情報が取得できないということなのですが、タグが違ってしまう原因はいくつかあります。
- 事業形態によって勘定科目が異なる
- IFRSやUSGAAP等会計基準が異なる
- 財務諸表が「個別」なのか「連結」なのかで勘定科目や取得情報が異なる
これらはすべてタグをつける上での判別基準になっているため、1つでも違うとkeyやcontext_refが変わってしまい、プログラムで情報を取得できなくなってしまいます。
こういったことが実際にあるため、事前に事業形態や会計基準などの企業の情報や、CSVファイルでタグになる情報などについて事前に調べることが重要になります。
極端な話、条件さえそろっていれば100件でも1000件でも自動で取得できます。
修正コード
今回の目的は「単体財務諸表の売上高を10社分取得する」ことです。先ほどのエラーの原因はタグが違ったため取得できませんでした。 そこで取得する対象企業のすべて会計基準が日本基準で、単体財務諸表の勘定科目に売上高のタグであるものに変更して再度抽出を試みます。
▼対象企業
- トヨタ自動車株式会社
- ソニーグループ株式会社
- 日産自動車株式会社
- 三菱自動車工業株式会社
- ヤマハ株式会社
- ダイキン工業株式会社
- カルビー株式会社
- 株式会社資生堂
- シャープ株式会社
- キヤノン株式会社
ファイルパスの部分を以上の企業のものに変更します。
# xbrlfile_financial_10companies.py
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
def get_revenue_from_xbrl(file_path, key, context_ref):
# XBRLファイルから売上高を取得する関数
parser = EdinetXbrlParser()
try:
xbrl_object = parser.parse_file(file_path)
revenue = xbrl_object.get_data_by_context_ref(key, context_ref).get_value()
return revenue
except Exception as e:
return f"データの取得に失敗しました。:{e}"
# 10社分のXBRLファイルパスをリストにまとめる
xbrl_file_paths = [
"xbrl_file\\Xbrl_Search_20240820_133855\\S100TR7I\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02144-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_133918\\S100TS7P\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01777-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134257\\S100TXFX\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02142-000_2024-03-31_01_2024-06-28.xbrl",
"xbrl_file\\Xbrl_Search_20240821_151530\\S100TPY6\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02213-000_2024-03-31_01_2024-06-21.xbrl",
"xbrl_file\\Xbrl_Search_20240821_151723\\S100TRUD\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02362-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152239\\S100TS9K\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01570-000_2024-03-31_01_2024-06-27.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152326\\S100TQWG\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E25303-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152355\\S100T45G\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E00990-000_2023-12-31_01_2024-03-26.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152852\\S100TXZ3\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01773-000_2024-03-31_01_2024-06-28.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152907\\S100T58N\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02274-000_2023-12-31_01_2024-03-28.xbrl"
]
# 対象企業の売上高を取得
key = "jppfs_cor:NetSales"
context_ref = "CurrentYearDuration_NonConsolidatedMember"
# 各企業から売上高を取得
for i, file_path in enumerate(xbrl_file_paths):
revenue = get_revenue_from_xbrl(file_path, key, context_ref)
print(f"企業{i+1}の売上高:{revenue}")Code language: PHP (php)結果
企業1の売上高:17575593000000
企業2の売上高:158726000000
企業3の売上高:4187227000000
企業4の売上高:2348961000000
企業5の売上高:262082000000
企業6の売上高:733157000000
企業7の売上高:204346000000
企業8の売上高:259361000000
企業9の売上高:527291000000
企業10の売上高:1668007000000無事すべての企業から売上高を出力することが確認できました。
念のため、有報で全て正しい数値かどうか確認しましたが正確なデータが取れていることが確認できました。
多数のXBRLファイルから自動で情報を取得
上記までのコードでは、取得したい情報がある有報のパスを直接コードに書き込むことによって機械に「ここにある書類から指定したkeyとcontext_refに該当する中身の情報を取ってきて」という命令をしています。
今回参照した有報の母数が10社で済んだためこのように一つひとつパスを書いても少し大変程度で済みした。しかし、1年分のすべての有報のようにもっと増えてしまうといちいちパスを書いてる余裕がありません。
ここで「正規表現」という技術を使います。これは「いくつかの文字列を一つの形式で表現するための表現方法」です。
# 変更前
# 10社分のXBRLファイルパスをリストにまとめる
xbrl_file_paths = [
"xbrl_file\\Xbrl_Search_20240820_133855\\S100TR7I\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02144-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_133918\\S100TS7P\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01777-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240820_134257\\S100TXFX\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02142-000_2024-03-31_01_2024-06-28.xbrl",
"xbrl_file\\Xbrl_Search_20240821_151530\\S100TPY6\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02213-000_2024-03-31_01_2024-06-21.xbrl",
"xbrl_file\\Xbrl_Search_20240821_151723\\S100TRUD\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02362-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152239\\S100TS9K\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01570-000_2024-03-31_01_2024-06-27.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152326\\S100TQWG\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E25303-000_2024-03-31_01_2024-06-25.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152355\\S100T45G\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E00990-000_2023-12-31_01_2024-03-26.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152852\\S100TXZ3\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E01773-000_2024-03-31_01_2024-06-28.xbrl",
"xbrl_file\\Xbrl_Search_20240821_152907\\S100T58N\\XBRL\\PublicDoc\\jpcrp030000-asr-001_E02274-000_2023-12-31_01_2024-03-28.xbrl"
]
# 変更後
# 10社分のXBRLファイルパスをリストにまとめる
xbrl_file_paths = glob.glob(r"XBRL_files\\Xbrl_Search_2024*\\*\\XBRL\\PublicDoc\\*.xbrl")Code language: PHP (php)今回では完全に同じ頭の部分と中の部分を指定し、違うものもあるところで「*」を使用します。これは「どんな文字が何文字でも入ってもいいですよ。」という意味のルールとなります。
つまり部分フィルタをかけているイメージです。このルールに当てはまるものすべてでコードを回し、現在と同じことを行えるようにするのです。極端にいえば、これに当てはまるものであれば10社のみと言わず数百、数千でも処理することができます。
なお、正規表現については他にもさまざまな便利な表現方法があり、Python以外の言語でも存在します。しかし、正規表現の書き方やそれぞれの言語での表記方法など詳しいことは本稿の趣旨と異なってしまうので割愛させていただきます。
次回以降の記事では複数社からデータを取得する際、同じく正規表現を用いて記述することになると思いますが、中身としては以上のようなことをしています。また、パスであることに変わりはないので保存先の名前によって皆さんことなってきますので、各自修正を忘れないようにお願いします。
まとめ
本稿では実際に売上という欲しいデータを指定し、1社と10社の場合で取得してみました。
1つから抜き出すことは割と容易にできたかもしれません。しかし、複数社から一気に抜き出すとなると思ってもみなかった障害があったことがわかっていただけたでしょうか。現場でXBRLを活用されている方たちは日々このような障害を乗り越えてXBRLを使用しているのです。
このように何でも自動で取得できる万能技術というわけにはいきませんが、準備をし条件さえ揃えば十分魅力的な技術であるということが伝わると嬉しいです。
次回は、今回と似たようなことで取得するデータを変えてみます。有報の文章の部分である非財務データ(テキストデータ)を取得しましょう。非財務データでは財務データよりもタグがしっかり振られていないデータが多く存在するためより大変になるかもしれません。
お楽しみに。
参考
Qiita “EDINETのXBRL用のPythonライブラリを作った – Parser編” 最終更新日:2019/1/19 閲覧日:2024/08/23
https://qiita.com/shoe116/items/dd362ad880f2b6baa96f
まるっとわかるXBRL入門:(1) 初心者のためのXBRL基礎

はじめに 世の中の上場企業は自身の会社の状況を決算短信や有価証券報告書(以下、有報)などの財務報告書を用いて説明する義務があります。 株主や投資家はこの財務報告書を見て、企業を分析し、投資を決心をします。 この世のすべて […]
まるっとわかるXBRL入門:(2) タクソノミとは?有価証券報告書を用いた企業データ分析のための前提知識を身に着けよう

はじめに タクソノミと言う言葉を聞いたことはありますか? タクソノミとは、情報・データなどの階層構造で整理したものを指し、XBRLの解析においては必要不可欠なものになります。 世の中の上場企業は自身の会社の状況を決算短信 […]
まるっとわかるXBRL入門:(3)大量の有価証券報告書を自動でダウンロードしよう

はじめに 世の中の上場企業は自身の会社の状況を決算短信や有価証券報告書(以下、有報)などを用いて説明する義務があります。株主や投資家は有報などを見て、企業を分析し、投資を決心をします。しかし、有報は1社につき約100ペー […]




